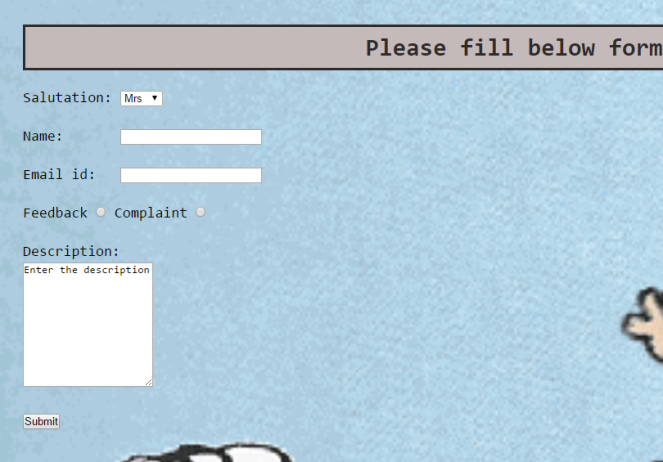
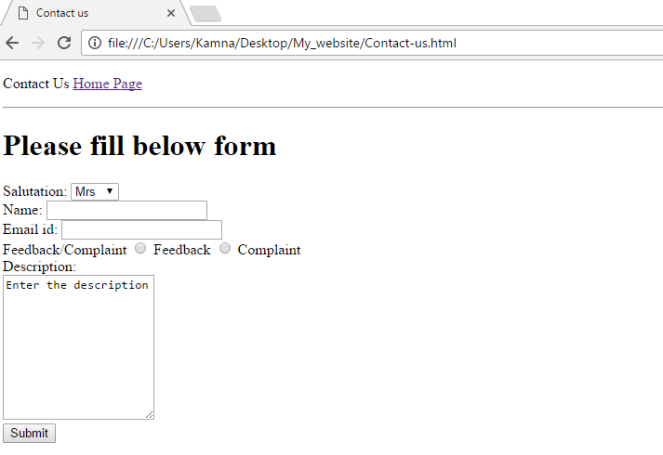
Below are some interview questions which I have faced in course of finding job. There is not any single answer to these questions and can be more elaborated answers but these will give you heads up for what questions to expect in an interview.
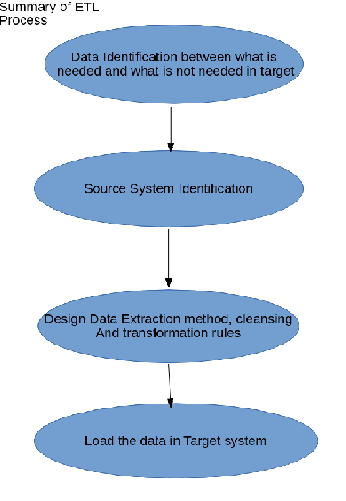
Q1: What is the end to end procedure followed in your project from processing ETL source files to reporting along with tools and technologies?
Ans: In my project below was the flow created
Source File–>ETL Jobs–>Stage Table–> ODS tables–>Data warehouse–>Data Cubes(Summarized data)–>Reporting tools
(In your project the process may be somewhat different)
Q2: What is the full form and use of ODS in data-warehouse?
Ans: Full form of ODS is Operational Data Store. Definition of ODS is : An operational data store (or “ODS“) is a database designed to integrate data from multiple sources for additional operations on the data. Unlike a master data store, the data is not passed back to operational systems. It may be passed for further operations and to the data warehouse for reporting.
Q3: How will you print name and salary of the employee from employee table who has maximum salary?
Ans: select name,salary from employees where salary = (select max(salary) from employees)
Q4: Why cant we use group by function in above question?
Ans: If you write query like below
select name,max(Salary) from employees group by salary.
It will give error saying “ORA-00923: not a single-group group function”. This issue comes when we try to select individual and group functions together , unless individual column is included in the group by clause.
Q5: How will you optimize the query in Teradata ?
Ans: Some of the query performing techniques is as below:
- See the explain plan and try understanding where the problem is
- Check if Primary Index is defined properly or not and if yes the data loaded is unique in the PI column
- If you have partitioned primary index created on the table, try to use it else the performance will be degraded
- Try avoiding use of functions in Join conditions such as TRIM etc
- Make sure there is no implicit conversion happening in join columns. Try to keep the data types same
- Try to avoid using IN column if there are more values to be compared. Try to use Join instead by may be creating static table for matching values.
These are just few tips and you can find more link
Q6: What are the typical scheduling software used for scheduling ETL jobs on Linux/Unix?
Ans: Autosys, Control-M are the 2 mostly used software for the scheduling need of ETL jobs. Some ETL tools come with their own schedulers but the are not flexible enough like tools specially meant for schedulers.
Q7: Give pros and cons of using Autosys as scheduling agent?
Ans: Pros:
- You can create jobs using its GUI version or JIL files
- It has vast variety of commands to handle the job scheduling and execution like you can force start it, you can make it start on arrival of file or at some particular time
- You can put the jobs on hold without really affecting the later jobs in it
Cons:
- If you have to create jil files for say hundreds of jobs things may get tedious
Q8: What are different type of dataware house schema?
Ans: Below are the different type of schema in DWH:
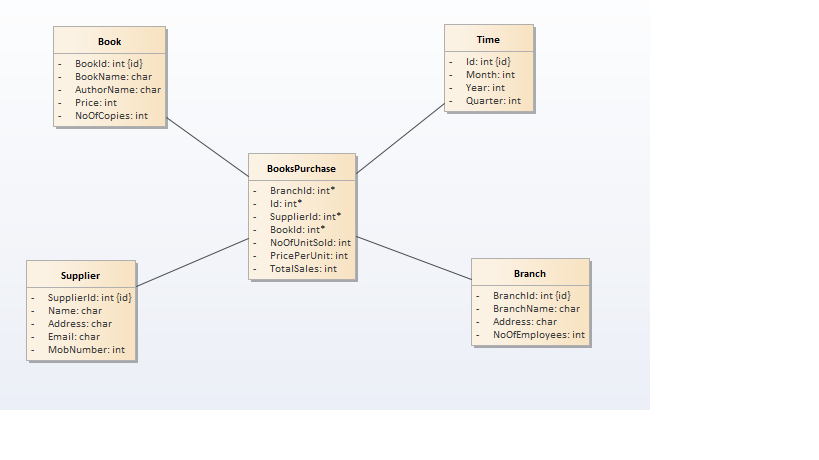
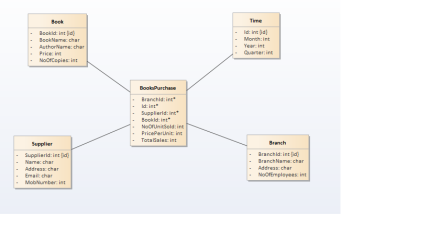
- Star Schema: Star schema resembles star with fact table in the centre and and dimension tables at the star points. This schema is the simplest of all the dataware house schemas. Below is the star schema of Library management system.
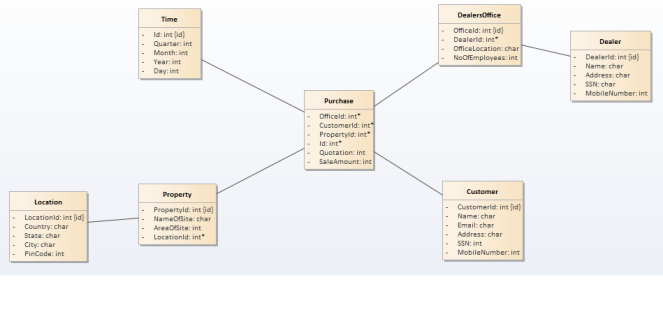
- Snow Flake Schema: One dimension is split in multiple dimensions. Snow flake schema is where we normalize the dimension tables of star schema. Below is the image f retail management snow flake schema
- Galaxy/Hybrid Schema: This the schema where conformed dimensions are used i.e. single dimension shared by multiple fact tables. Dimensions can be further normalized in these type of schemas.
Q9: What is SCD and describe different type of SCDs?
Ans: SCD means slowly changing dimensions i.e. dimensions whose attributes change slowly over the period of time. Say a customer whose address may change several times over the years.
There are 3 type of SCD implementations in DWH:
- SCD Type 1 : Overwrite the old value
- SCD Type 2: Add a new row
- SCD Type 3 : Add a new column
Q10: How will you implement SCD type 2 in banking system?
Ans: Suppose a customer is changing an address then it will be implemented as below:
Initial record:
| Actual Customer Table |
| id |
name |
year |
address |
| 1 |
ABC |
2016 |
Boston |
Now this customer changes the address, we can capture this change by adding new row and start and end dates
| SD2 Customer Table |
| id |
name |
address |
start_date |
end_date |
| 1 |
ABC |
Boston |
01-01-2015 |
31-12-2016 |
| 1 |
ABC |
Portland |
01-01-2017 |
01-01-2099 |
In this implementation start_date should be when first record came and end_date can be updated with date when change in address happens with end date is some future date.
These are few questions I encountered during KP’s interview. Please help me increase in the list by adding other questions in the comments.
Some Information is collected from www.wikipedia.com